[JSCode 자바 스터디] 3주차(1) - 컬렉션
📌 컬렉션
JCF란?
- Java Collection Framework로 다량의 데이터를 효과적으로 처리하는 표준화된 방법을 제공하는 프레임워크이다.
👉 JCF 구조
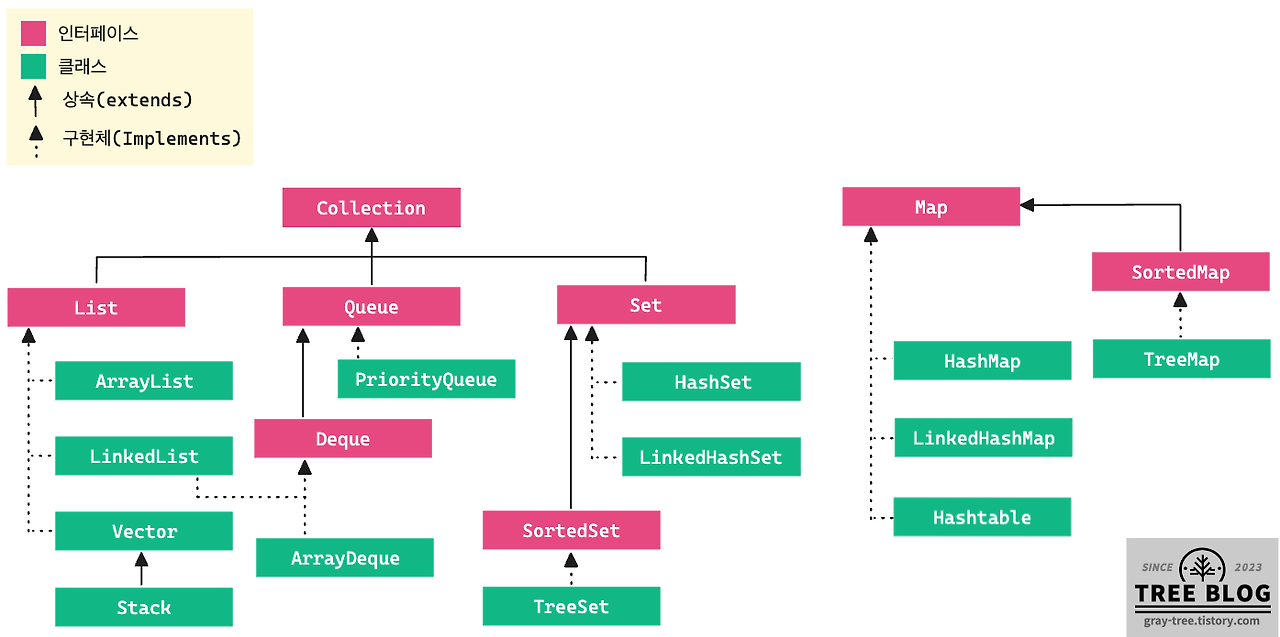
Collection과 Map으로 이루어져 있다.
Collection은 Iterator을 extends 한다. import java.util` 을 통해 사용할 수 있으며 List, Queue, Set, Map이 있다.
- List: 순서가 있는 데이터의 집합으로 중복값을 허용함
- Set: 순서가 없는 데이터의 집합으로 중복을 허용하지 않음
- Map: 키-값 쌍으로 이루어진 데이터의 집합으로 키는 중복될 수 없고, 값은 중복이 가능
- Queue: FIFO구조로, 먼저 입력된 값이 먼저 나옴
👉 List ( ArrayList/LinkedList/Vector )
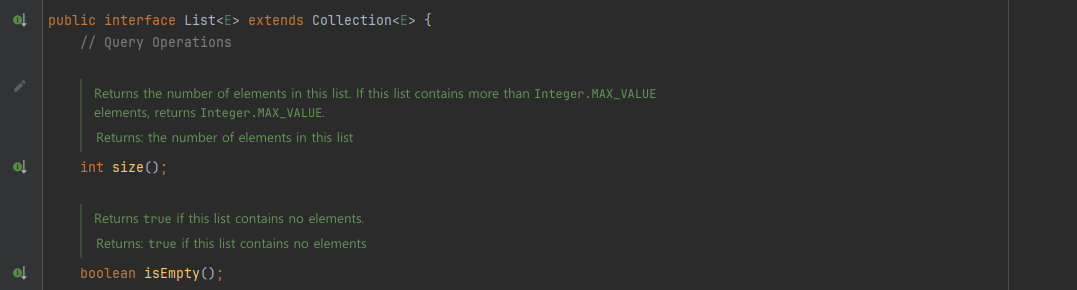 실제 자바에서 List 인터페이스로 들어가면 위와 같이 생겼다.
실제 자바에서 List 인터페이스로 들어가면 위와 같이 생겼다.
1
2
3
4
5
6
int size(); //사이즈를 반환해줌
boolean isEmpty(); //empty 유무 반환
boolean contains(Object o);
boolean add(E e); //값을 삽입
boolean remove(Object o); //값을 제거
boolean containsAll(Collection<?> c); //값이 저장되어있는지 유무
인터페이스의 내용은 위와 같다. 다양한 함수를 제공한다. List 인터페이스의 구현체는 ArrayList, LinkedList, Vector가 있다.
ArrayList
- 동적 배열로 길이가 가변적이다.
- 기본 길이는 10으로 할당된다.
- 메모리는 연결되어있지 않으며 주소로 연결되어 있다.
- element 사이의 공간을 허용하지 x
- 데이터를 객체로 다룬다.
👉 어떻게 메모리 크기를 확장할까?
- ArrayList는 내부적으로 elementData 배열과 size를 가지고 있다.
- element의 개수와 size가 일치하면 grow() 메서드를 호출
- size+1 크기의 새로운 elementData 객체를 생성하고, 기존 값을 복사
- 그런데 shift연산이라 실제로는 1.5배라고 한다(?)
LinkedList
- 노드(객체)끼리 서로의 포인터를 가리키며 링크하며 연결되어있다.
- 각 노드는 다음 노드의 주소와 데이터를 가지고 있다.
- 이중 연결리스트로 빠른 삽입/삭제 가능
Vector
- ArrayList와 유사
- thread-safe함(현재는 ArrayList를 주로 사용함)
👉 Queue/Set
Queue
- FIFO(Frist In First Out)
- 생성자가 없는 인터페이스이다.
1
Queue<Integer> intQueue = new LinkedList<>(); // queue를 생성, 선언
- 이와 같이 선언해준다.
1
2
3
4
5
6
boolean add(E e); //삽입 성공 시 true, 실패 시 Exception발생
boolean offer(E e); //삽입 성공 시 true, 실패 시 false 반환
E remove(); //삭제된 value, 공백 큐이면 Exception("NoSuchElementException") 발생
E poll(); //삭제된 value의 자료형
E element(); //큐 head에 위치한 value의 자료형
E peek(); //큐 head에 위치한 value의 자료형
Set
- 순서가 없는 데이터의 집합이다.
- 중복을 허용하지 않는다.
👉 인덱스가 없는 Set의 데이터중복 확인 방법? 
- Set 객체가 생성될 때 Heap 메모리에 객체의 메모리 주소가 담긴 데이터를 저장
- 이것으로 HashCode를 생성하고 이미 저장되어 있는 객체들의 해시코드와 비교
- equals() 함수를 통해 두 객체를 비교하고, true로 나오면 저장하지 X
👉 Map
- 위의 JSF 구조를 보면 알겠지만, Map 인터페이스는 Collection 과는 다르다.
- Key-Value 방식으로 데이터를 저장하기 때문이다.
- 저장 순서를 유지하지 않는다.
- 키의 중복 X, 값의 중복은 허용
구현 클래스
- HashMap<K, V>
- Hashtable<K, V>
- TreeMap<K, V>
👉 HashMap
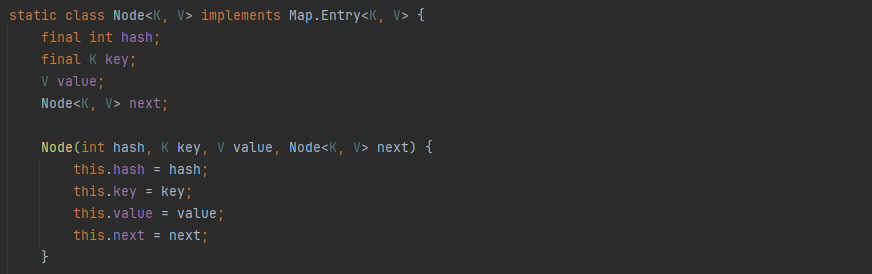
- 내부적으로 해시 테이블을 사용하여 데이터의 추가, 검색, 삭제 등의 작업이 빠르다.
- Key의 해시 값을 사용해 값을 저장하고 조회
- 키-값 쌍의 개수에 따라 동적으로 크기가 증가하는 associate array이다.
- 이때, associate array란 키 하나와 값 하나가 연관되어 있으며 키를 통해 연관되는 값을 얻을 수 있는 자료 구조이다.
- initialCapacity(초기 용량, 버킷의 수) : 기본 16
- loadFactor(부하 계수) : 얼마나 차있을 때 테이블을 확장할 것인가? 기본 0.75
👉 해시맵의 스레드
- 해시맵은 Thread Safe 하지 않다.
- 여러 스레드가 동시에 HashMap에 접근하고 수정할 경우 동시성을 보장 x
Collections.synchronizedMap(),ConcurrentHashMap을 사용하면 이를 해결할 수 있다.
👉 만약 해싱충돌이 일어나면 어떻게 해결하는가?
- 체이닝: 해당 버킷의 연결리스트로 새로운 키-값 쌍 추가
- 개방 주소법: 다른 버킷을 찾아 저장한다. (버킷을 찾는 방법으로는
선형조사,제곱조사,이중해싱이 있다.) - 레드-브랙 트리 사용해 하나의 해시 버킷에 8개의 키-값 쌍이 모이면 연결 리스트를 트리로 변경하고, 데이터를 삭제해 개수가 6개가 되면 다시 연결 리스트로 변경한다.
👉 레드 블랙 트리 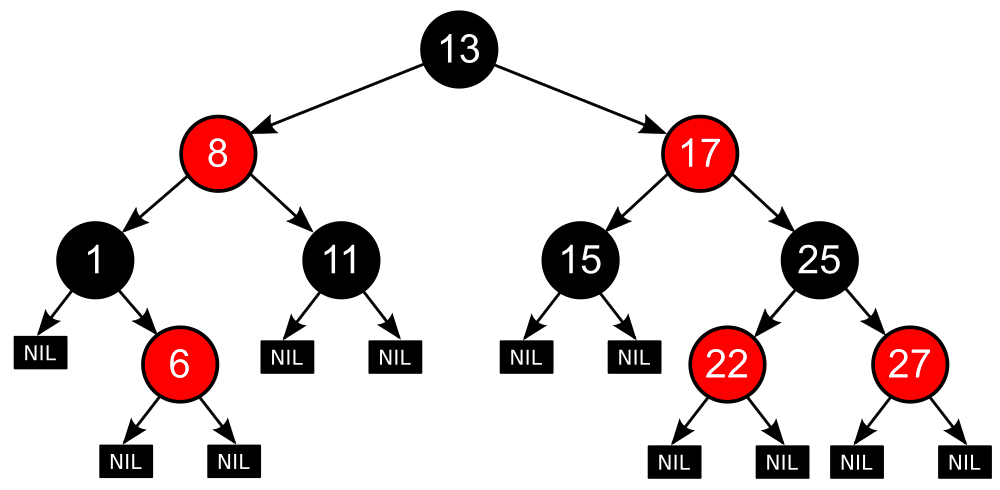
- 루트 노드는 검은색
- 빨간색 노드의 자식은 무조건 검은색
- 모든 리프 노드에서 Black Depth는 같다.
참고
https://f-lab.kr/insight/understanding-java-hashmap-and-best-practices?gad_source=2&gclid=EAIaIQobChMIhYX4vNzbiQMVvNIWBR01GQ9bEAAYASAAEgJ5U_D_BwE https://chaewsscode.tistory.com/183
This post is licensed under CC BY 4.0 by the author.